4 Descriptive statistics
Learning objectives:
- Calculate and interpret the arithmetic mean, median, mode, range, variance, and standard deviation of a dataset.
- Understand the concepts of skewness and kurtosis to describe the shape of data distribution.
- Distinguish between standard deviation and standard error, and compute the standard error of the mean.
- Learn the calculation and application of the coefficient of variation as a relative measure of variability.
- Grasp the fundamentals of covariance and the correlation coefficient to measure the relationship between two variables.
- Understand that corelation does not imply causation and that causation does not require corelation.
- Explore the Spearman rank correlation coefficient for non-parametric data analysis.
- Apply these statistical measures to real-world datasets through exercises and supplementary video materials.
4.1 Univariate data
4.1.1 Arithmetic mean
The arithmetic mean (\(\bar{x}\)) is calculated as the sum of all the values in a dataset divided by the total number of values:
\[\bar{x} = \frac{{\sum_{i=1}^{n} x_i}}{n}\]
where \(\bar{x}\) represents the arithmetic mean, \(x_i\) represents each individual value in the dataset, and \(n\) represents the total number of values in the dataset.
4.1.2 Median
The median is the middle value of a dataset when it is sorted in ascending or descending order. If the dataset has an odd number of values, the median is the middle value. If the dataset has an even number of values, the median is the average of the two middle values.
4.1.3 Mode
The mode is the value or values that appear most frequently in a dataset.
4.1.4 Range
The range is the difference between the maximum and minimum values in a dataset.
\[ \text{{Range}} = \max(x_i) - \min(x_i) \]
where \(\text{{Range}}\) represents the range value, and \(x_i\) represents each individual value in the dataset.
4.1.5 Variance
The variance represents the average of the squared deviations of a random variable from its mean. It quantifies the extent to which a set of numbers deviates from their average value. Variance is commonly denoted as \(Var(X)\), \(\sigma^2\), or \(s^2\). The calculation of variance is as follows: \[ \sigma^2={\frac{1}{n}}\sum _{i=1}^{n}(x_{i}-\mu )^{2} \] However, it is better to use \[ \sigma^2={\frac{1}{n-1}}\sum _{i=1}^{n}(x_{i}-\mu )^{2}. \]
The use of \(n - 1\) instead of \(n\) in the formula for the sample variance is known as Bessel’s correction, which corrects the bias in the estimation of the population variance, and some, but not all of the bias in the estimation of the population standard deviation. Consequently this way to calculate the variance and hence the standard deviation is called the sample standard deviation or the unbiased estimation of standard deviation. In other words, when working with a sample instead of the full population the limited number of observations tend to be closer to the sample mean than to the population mean, see Figure 4.2. Bessels Correction takes that into account.
For a detailed explanation, you can watch the video shown in Figure 4.1.

StatQuest with Josh Starmer: Why Dividing By N Underestimates the Variance :::
1 Picture is taken from the video https://youtu.be/sHRBg6BhKjI
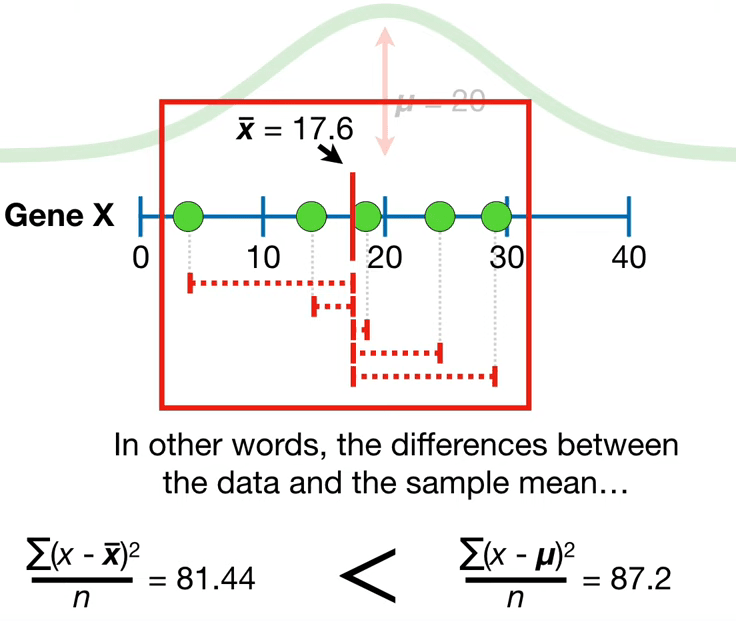
4.1.6 Standard deviation
As the variance is hard to interpret, the standard deviation is a more often used measure of dispersion. A low standard deviation indicates that the values tend to be close to the mean. It is often abbreviated with \(sd\), \(SD\), or most often with the Greek letter sigma, \(\sigma\). The underlying idea is to measure the average deviation from the mean. It is calculated as follows: \[ sd(x)=\sqrt{\sigma^2}={\sqrt {{\frac {1}{n-1}}\sum _{i=1}^{n}\left(x_{i}-{\mu}\right)^{2}}}=\sigma \]
4.1.7 Standard error
The standard deviation (SD) measures the amount of variability, or dispersion, for a subject set of data from the mean, while the standard error of the mean (SEM) measures how far the sample mean of the data is likely to be from the true population mean. The SEM is always smaller than the SD. It matters because it helps you estimate how well your sample data represents the whole population.
The standard error of the mean (SEM) can be expressed as: \[ sd(\bar{x})=\sigma_{\bar {x}}\ = s = {\frac {\sigma }{\sqrt {n}}} \] where \(\sigma\) is the standard deviation of the population and \(n\) is the size (number of observations) of the sample.
Also see the video by StatQuest with Josh Starmer: Standard Deviation vs Standard Error, Clearly Explained!!!:
Why divide by the square root of \(n\)?
Let \(X_{i}\) be an independent draw from a distribution with mean \(\bar{x}\) and variance \(\sigma^{2}\). What is the variance of \(\bar{x}\)?
By definition: \[ \operatorname{Var}(x)=E\left[\left(x_{i}-E\left[x_{i}\right]\right)^{2}\right]=\sigma^{2} \] so \[\begin{align*} \operatorname{Var}(\bar{x})&=E\left[\left(\frac{\sum x_{i}}{n}-E \left[\frac{\sum x_{i}}{n}\right]\right)^{2}\right]\\ &=E\left[\left(\frac{\sum x_{i}}{n}-\frac{1}{n} E\left[ \sum x_{i}\right]\right)^{2}\right]\\ &=\frac{1}{n^{2}} E\left[\left(\sum x_{i}-E\left[\sum x_{i}\right]\right)^{2}\right]\\ &=\frac{1}{n^{2}} E\left[\left(\sum x_{i}- \sum \bar{x}\right)^{2}\right]\\ &=\frac{1}{n^{2}} E\left[(x_{1}+x_{2}+\cdots+x_{n}-\underbrace{\bar{x}-\bar{x}-\cdots -\bar{x}}_{n \text{ terms }})^{2}\right]\\ &=\frac{1}{n^{2}} E\left[\sum\left(x_{i}-\bar{x}\right)^{2}\right]\\ &=\frac{1}{n^{2}} \sum E\left(x_{i}-\bar{x}\right)^{2}\\ &=\frac{1}{n^{2}} \underbrace{\sum \sigma^{2}}_{n\cdot \sigma^{2}}\\ &=\frac{1}{n} \sigma^{2} \end{align*}\] and hence \[ sd(\bar x)=\sqrt{\operatorname{Var}(\bar{x})}=s={\frac {\sigma }{\sqrt {n}}} \]
4.1.8 Coefficient of variation
The coefficient of variation (\(CoV\)) is a relative measure of variability and is calculated as the ratio of the standard deviation to the mean, expressed as a percentage:
\[ CoV = \frac{\sigma}{\bar{x}} \]
where \(CoV\) represents the coefficient of variation, \(\sigma\) represents the standard deviation, and \(\bar{x}\) represents the arithmetic mean.
4.1.9 Skewness
Skewness is a measure of the asymmetry of a distribution. There are different formulas to calculate skewness, but one common method is using the third standardized moment (\(\gamma_1\)):
\[ \gamma_1 = \frac{{\sum_{i=1}^{n} \left(\frac{x_i - \bar{x}}{\sigma}\right)^3}}{n} \] where \(\gamma_1\) represents the skewness, \(x_i\) represents each individual value in the dataset, \(\bar{x}\) represents the arithmetic mean, \(\sigma\) represents the standard deviation, and \(n\) represents the total number of values in the dataset.
4.1.10 Kurtosis
Kurtosis measures the peakedness or flatness of a probability distribution. There are different formulations for kurtosis, and one of the common ones is the fourth standardized moment. The formula for kurtosis is given by:
\[ \text{Kurtosis} = \frac{{\frac{1}{n} \sum_{i=1}^{n}(x_i - \bar{x})^4}}{{\left(\frac{1}{n} \sum_{i=1}^{n}(x_i - \bar{x})^2\right)^2}} \] where \(\text{Kurtosis}\) represents the kurtosis value, \(x_i\) represents each individual value in the dataset, \(\bar{x}\) represents the mean of the dataset, and \(n\) represents the total number of values in the dataset.
4.2 Bivariate data
4.2.1 Covariance
Covariance \(Cov(X,Y)\) (or \(\sigma_{XY}\)) is a measure of the joint variability of two variables (\(x\) and \(y\)) and their observations \(i\), respectively. The covariance is positive when larger values of one variable tend to correspond with larger values of the other variable, or when smaller values of one variable tend to correspond with smaller values of the other variable. On the other hand, a negative covariance suggests an inverse relationship, where larger values of one variable tend to correspond with smaller values of the other variable.
It’s important to note that the magnitude of the covariance is influenced by the units of measurement, making it challenging to interpret directly. Additionally, the spread of the variables also affects the covariance. The formula for calculating covariance is as follows: \[ \operatorname{Cov}(X,Y)=\sigma_{XY}={\frac {1}{n-1}}\sum _{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y}) \] where \(cov(X,Y)\) represents the covariance, \(\sigma_{XY}\) is an alternative notation, \(x_i\) and \(y_i\) are the individual observations of variables \(X\) and \(Y\), \(\bar{x}\) and \(\bar{y}\) are the means of variables \(X\) and \(Y\), and \(n\) is the total number of observations.
To gain a better understanding of the concept and calculation of covariance, I highly recommend watching Josh Starmer’s informative and visually engaging video titled Covariance and Correlation Part 1: Covariance:
4.2.2 The correlation coefficient (Bravais-Pearson)
The Pearson correlation coefficient measures the linear relationship between two variables. It is calculated as the covariance of the variables divided by the product of their standard deviations. \[ \rho_{X,Y} = \frac{{\text{Cov}(X, Y)}}{{\sigma_X \sigma_Y}} \] where \(\rho\) represents the Pearson correlation coefficient, \(\text{Cov}(X, Y)\) denotes the covariance between variables \(X\) and \(Y\), \(\sigma_X\) denotes the standard deviation of variable \(X\), and \(\sigma_Y\) denotes the standard deviation of variable \(Y\). It has a value between +1 and -1.
By dividing the covariance of \(X\) and \(Y\) by the multiplication of the standard deviations of \(X\) and \(Y\), the correlation coefficient is normalized by having a minimum of -1 and a maximum of 1. Thus, it can fix the problem of the variance that the scale (unit of measurement) determines the size of the variance.
I highly recommend watching the video Pearson’s Correlation, Clearly Explained!!! StatQuest with Josh Starmer. It provides a clear and engaging explanation of the meaning of correlation. The video features informative animations that help visualize the concept:
In interpreting correlations, it is important to remember that they…
- … only reflect the strength and direction of linear relationships,
- … do not provide information about the slope of the relationship, and
- … fail to explain important aspects of nonlinear relationships.
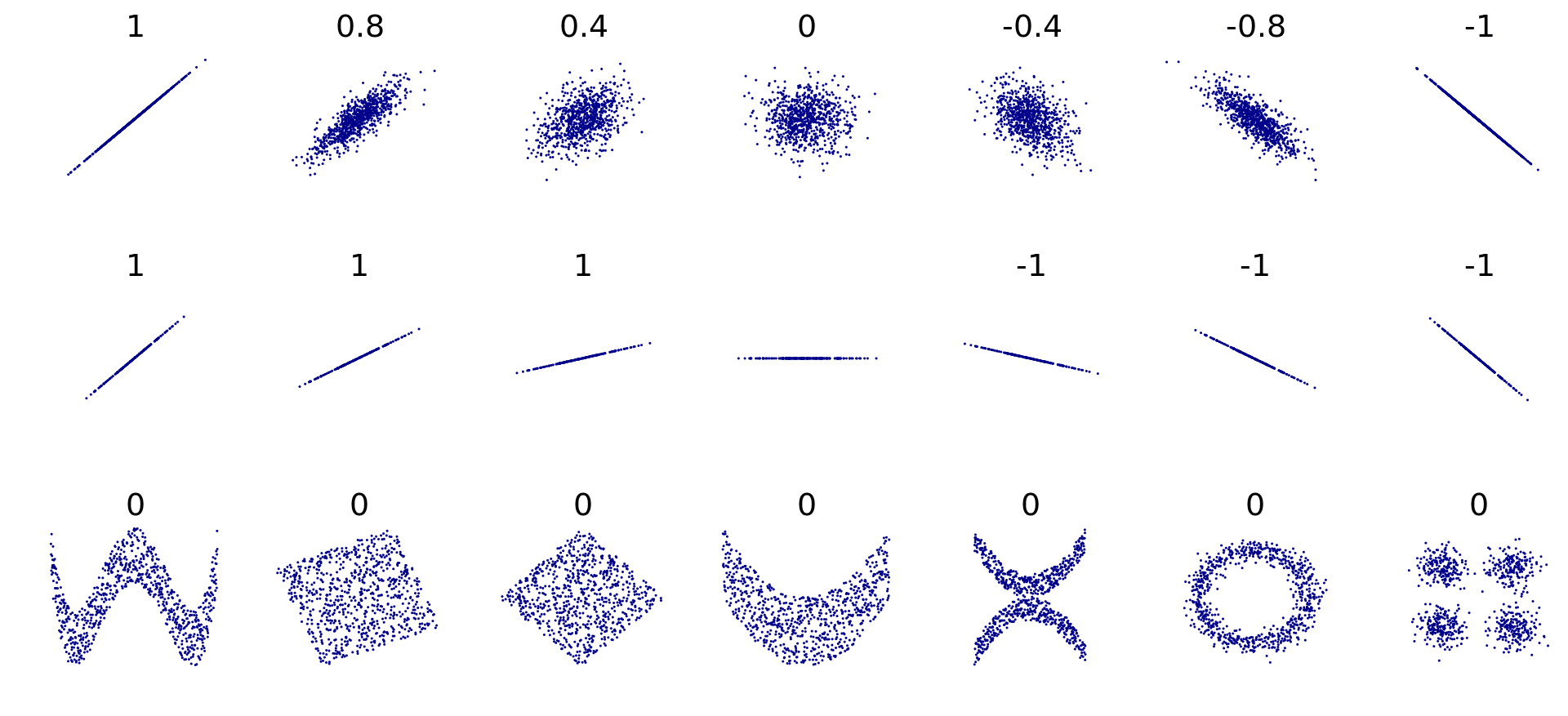
Figure 4.3 shows that correlation coefficients are limited in to explaining the relationship of two variables. For example, when the slope of a relationship is zero, the correlation coefficient becomes undefined due to the variance of \(Y\) being zero. Furthermore, Pearson’s correlation coefficient is sensitive to outliers, and all correlation coefficients are prone to sample selection biases. It is crucial to be careful when attempting to correlate two variables, particularly when one represents a part and the other represents the total. It is also worth noting that small correlation values do not necessarily indicate a lack of association between variables. For example, Pearson’s correlation coefficient can underestimates the association between variables exhibiting a quadratic relationship. Therefore, it is always advisable to examine scatterplots in conjunction with correlation analysis.
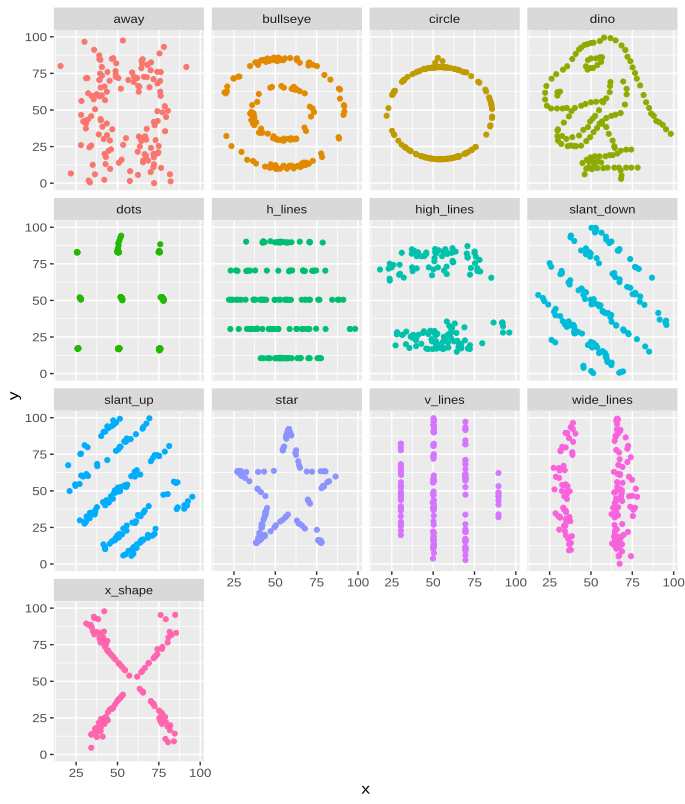
In Figure 4.4 you see various graphs that all have the same correlation coefficient and share other statistical properties like is investigated in Exercise 4.2.
2 This graph was produced employing the datasauRus R package.
4.2.3 Rank correlation coefficient (Spearman)
Spearman’s rank correlation coefficient is a measure of the strength and direction of the monotonic relationship between two variables. It can be calculated for a sample of size \(n\) by converting the \(n\) raw scores \(X_i, Y_i\) to ranks \(\text{R}(X_i), \text{R}(Y_i)\), then using the following formula:
\[ r_s = \rho_{\operatorname{R}(X),\operatorname{R}(Y)} = \frac{\text{cov}(\operatorname{R}(X), \operatorname{R}(Y))}{\sigma_{\operatorname{R}(X)} \sigma_{\operatorname{R}(Y)}}, \] where \(\rho\) denotes the usual Pearson correlation coefficient, but applied to the rank variables, \(\operatorname{cov}(\operatorname{R}(X), \operatorname{R}(Y))\) is the covariance of the rank variables, \(\sigma_{\operatorname{R}(X)}\) and \(\sigma_{\operatorname{R}(Y)}\) are the standard deviations of the rank variables.
If all \(n\) ranks are distinct integers, you can use the handy formula: \[ \rho = 1 - \frac{6\sum d_i^2}{n(n^2 - 1)} \] where \(\rho\) denotes the correlation coefficient, \(\sum d_i^2\) is the sum of squared differences between the ranks of corresponding pairs of variables, and \(n\) represents the number of pairs of observations.
The coefficient ranges from -1 to 1. A value of 1 indicates a perfect increasing monotonic relationship, while a value of -1 indicates a perfect decreasing monotonic relationship. A value of 0 suggests no monotonic relationship between the variables.
Spearman’s rank correlation coefficient is a non-parametric measure and is often used when the relationship between variables is not linear or when the data is in the form of ranks or ordinal categories.
4.3 Exercises
Exercise 4.2 DatasauRus (Solution online.)
The following exercise shows how to create Figure 4.4 using the programming language R. Solutions to this can be found here and in my lecture notes: Huber (2025) on How to Use R for Data Science.

Load the packages
datasauRusandtidyverse. If necessary, install these packages.The package
datasauRuscomes with a dataset in two different formats:datasaurus_dozenanddatasaurus_dozen_wide. Store them asdsandds_wide.Open and read the R vignette of the
datasauRuspackage. Also open the R documentation of the datasetdatasaurus_dozen.Explore the dataset: What are the dimensions of this dataset? Look at the descriptive statistics.
How many unique values does the variable
datasetof the tibbledshave? Hint: The function unique() return the unique values of a variable and the function length() returns the length of a vector, such as the unique elements.Compute the mean values of the
xandyvariables for each entry indataset. Hint: Use the group_by() function to group the data by the appropriate column and then the summarise() function to calculate the mean.Compute the standard deviation, the correlation, and the median in the same way. Round the numbers.
What can you conclude?
Plot all datasets of
ds. Hide the legend. Hint: Use thefacet_wrap()and thetheme()function.Create a loop that generates separate scatter plots for each unique datatset of the tibble
ds. Export each graph as a png file.Watch the video Animating the Datasaurus Dozen Dataset in R from The Data Digest on YouTube: